17 Extensions of Logistic Regression - Ex: Canadian Women’s Labour-Force Participation
17.1 PREPARATION
17.1.2 Background
The Womenlf data frame has 263 rows and 4 columns. The data are from a 1977 survey of the Canadian population.
Dependent variable (DV) or outcome
particLabour-Force Participation, a factor with levels:fulltimeWorking full-time
not.workNot working outside the home
parttimeWorking part-time
Indepdentend variables (IV) or predictors
hincomeHusband’s income, in $1000’schildrenPresence of children in the household, a factor with levels:
absentno children in the home
presentat least one child at homeregionA factor with levels:
AtlanticAtlantic CanadaBCBritish ColumbiaOntarioPrairiePrairie provincesQuebec
17.1.3 Raw Dataset
The data is included in the carData package which installs and loads with the car package.
data(Womenlf, package = "carData") # load the internal data
tibble::glimpse(Womenlf) # glimpse a bit of the dataRows: 263
Columns: 4
$ partic <fct> not.work, not.work, not.work, not.work, not.work, not.work, n…
$ hincome <int> 15, 13, 45, 23, 19, 7, 15, 7, 15, 23, 23, 13, 9, 9, 45, 15, 5…
$ children <fct> present, present, present, present, present, present, present…
$ region <fct> Ontario, Ontario, Ontario, Ontario, Ontario, Ontario, Ontario…Womenlf %>%
dplyr:: filter(row_number() %in% sample(1:nrow(.), size = 10)) # select a random sample of 10 rows# A tibble: 10 × 4
partic hincome children region
<fct> <int> <fct> <fct>
1 not.work 23 present Ontario
2 not.work 23 present Prairie
3 not.work 23 present Ontario
4 parttime 23 present Ontario
5 parttime 19 present Ontario
6 not.work 15 present Atlantic
7 not.work 19 present Quebec
8 not.work 19 present Quebec
9 fulltime 6 present Quebec
10 not.work 15 present Quebec Notice the order of the factor levels, especially for the partic factor
'data.frame': 263 obs. of 4 variables:
$ partic : Factor w/ 3 levels "fulltime","not.work",..: 2 2 2 2 2 2 2 1 2 2 ...
$ hincome : int 15 13 45 23 19 7 15 7 15 23 ...
$ children: Factor w/ 2 levels "absent","present": 2 2 2 2 2 2 2 2 2 2 ...
$ region : Factor w/ 5 levels "Atlantic","BC",..: 3 3 3 3 3 3 3 3 3 3 ...We can view the order of the factors levels
[1] "fulltime" "not.work" "parttime"17.1.4 Declare Factors
df_wo <- Womenlf %>%
dplyr::mutate(working_ord = partic %>%
forcats::fct_recode("Full Time" = "fulltime",
"Not at All" = "not.work",
"Part Time" = "parttime") %>%
factor(levels = c("Not at All",
"Part Time",
"Full Time"))) %>%
dplyr::mutate(working_any = dplyr::case_when(
partic %in% c("fulltime", "parttime") ~ "At Least Part Time",
partic == "not.work" ~ "Not at All") %>%
factor(levels = c("Not at All",
"At Least Part Time"))) %>%
dplyr::mutate(working_full = dplyr::case_when(
partic == "fulltime" ~ "Full Time",
partic %in% c("not.work", "parttime") ~ "Less Than Full Time")%>%
factor(levels = c("Less Than Full Time",
"Full Time"))) %>%
dplyr::mutate(working_type = dplyr::case_when(
partic == "fulltime" ~ "Full Time",
partic == "parttime" ~ "Part Time")%>%
factor(levels = c("Part Time",
"Full Time"))) %>%
dplyr::mutate_if(is.factor, ~forcats::fct_relabel(.x, stringr::str_to_title)) Display the structure of the ‘clean’ version of the dataset
'data.frame': 263 obs. of 8 variables:
$ partic : Factor w/ 3 levels "Fulltime","Not.work",..: 2 2 2 2 2 2 2 1 2 2 ...
$ hincome : int 15 13 45 23 19 7 15 7 15 23 ...
$ children : Factor w/ 2 levels "Absent","Present": 2 2 2 2 2 2 2 2 2 2 ...
$ region : Factor w/ 5 levels "Atlantic","Bc",..: 3 3 3 3 3 3 3 3 3 3 ...
$ working_ord : Factor w/ 3 levels "Not At All","Part Time",..: 1 1 1 1 1 1 1 3 1 1 ...
$ working_any : Factor w/ 2 levels "Not At All","At Least Part Time": 1 1 1 1 1 1 1 2 1 1 ...
$ working_full: Factor w/ 2 levels "Less Than Full Time",..: 1 1 1 1 1 1 1 2 1 1 ...
$ working_type: Factor w/ 2 levels "Part Time","Full Time": NA NA NA NA NA NA NA 2 NA NA ...17.2 EXPLORATORY DATA ANALYSIS
Three versions of the outcome
df_wo %>%
dplyr::select(working_ord,
working_any,
working_full,
working_type) %>%
apaSupp::tab_freq(caption = "Different Ways to Code the Categorical 'Working' Variable")Statistic | ||
|---|---|---|
working_ord | ||
Not At All | 155 (58.9%) | |
Part Time | 42 (16.0%) | |
Full Time | 66 (25.1%) | |
working_any | ||
Not At All | 155 (58.9%) | |
At Least Part Time | 108 (41.1%) | |
working_full | ||
Full Time | 66 (25.1%) | |
Less Than Full Time | 197 (74.9%) | |
working_type | ||
Part Time | 42 (16.0%) | |
Full Time | 66 (25.1%) | |
Missing | 155 (58.9%) | |
Other Predisctors, univariate
df_wo %>%
dplyr::select(working_ord,
"Husband's Income, $1000's" = hincome,
"Children In the Home" = children,
"Region of Canada" = region) %>%
apaSupp::tab1(split = "working_ord",
caption = "Descriptive Summary of Participants by Working Status")
| Total | Not At All | Part Time | Full Time | p-value |
|---|---|---|---|---|---|
Husband's Income, $1000's | 14.76 (7.23) | 15.58 (7.16) | 15.95 (8.08) | 12.06 (6.15) | < .001*** |
Children In the Home | < .001*** | ||||
Absent | 79 (30.0%) | 26 (16.8%) | 7 (16.7%) | 46 (69.7%) | |
Present | 184 (70.0%) | 129 (83.2%) | 35 (83.3%) | 20 (30.3%) | |
Region of Canada | .710 | ||||
Atlantic | 30 (11.4%) | 20 (12.9%) | 4 (9.5%) | 6 (9.1%) | |
Bc | 29 (11.0%) | 14 (9.0%) | 8 (19.0%) | 7 (10.6%) | |
Ontario | 108 (41.1%) | 64 (41.3%) | 17 (40.5%) | 27 (40.9%) | |
Prairie | 31 (11.8%) | 17 (11.0%) | 6 (14.3%) | 8 (12.1%) | |
Quebec | 65 (24.7%) | 40 (25.8%) | 7 (16.7%) | 18 (27.3%) | |
Note. Continuous variables are summarized with means (SD) and significant group differences assessed via independent one-way analysis of vaiance (ANOVA). Categorical variables are summarized with counts (%) and significant group differences assessed via Chi-squared tests for independence. | |||||
* p < .05. ** p < .01. *** p < .001. | |||||
17.2.1 Husband’s Income
Figure 17.1
Distribution of Husband’s Income
df_wo %>%
ggplot(aes(x = working_ord,
y = hincome,
group = working_ord)) +
geom_violin(fill = "gray") +
geom_boxplot(width = .25) +
geom_jitter(position=position_jitter(0.2)) +
stat_summary(fun.y = mean,
geom = "errorbar",
aes(ymax = ..y..,
ymin = ..y..),
width = .75,
color = "red",
size = 1) +
theme_bw() +
labs(x = "Wife's Working Status",
y = "Husband's Income, $1000's")
df_wo %>%
ggplot(aes(hincome,
x = working_ord)) +
geom_boxplot(alpha = .3,
fill = "gray30") +
theme_bw() +
labs(x = "Wife's Working Status",
y = "Husband's Income, $1000's")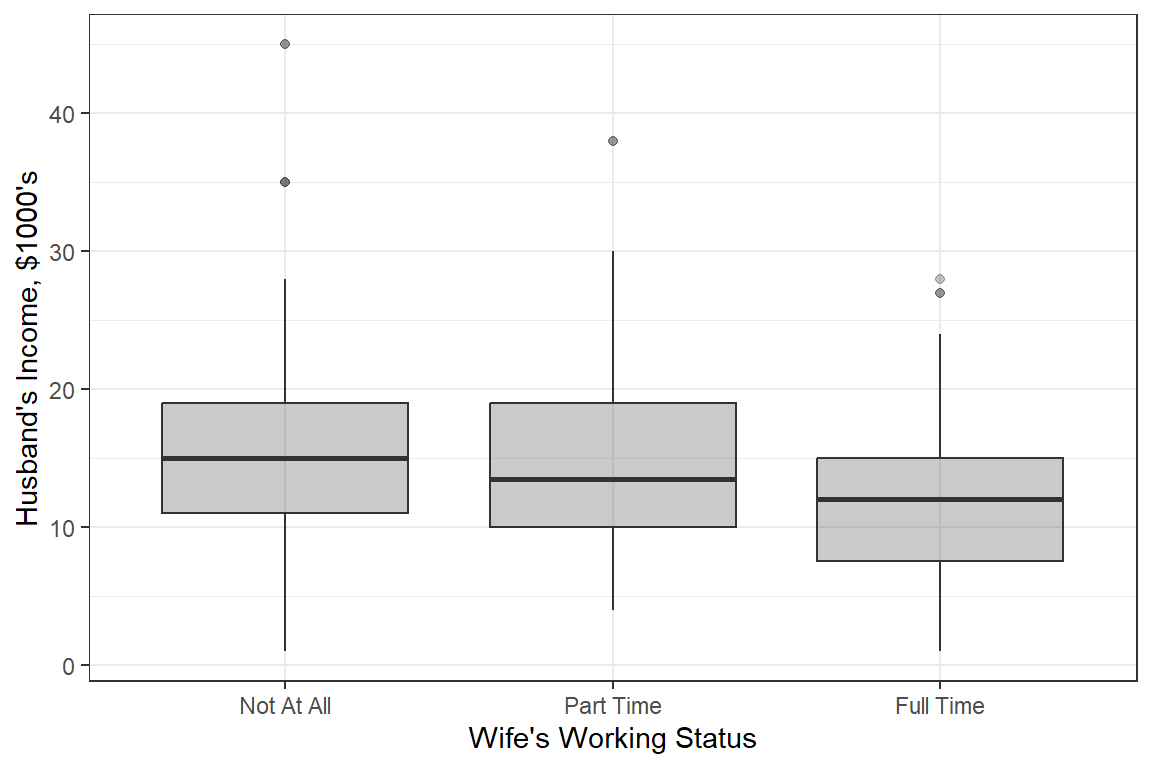
17.2.2 Children in Home
df_wo %>%
ggplot(aes(x = children,
fill = working_ord %>% fct_rev)) +
geom_bar(position="fill") +
labs(x = "Children in the Home",
y = "Proportion of Women",
fill = "Working") +
theme_bw() +
scale_fill_manual(values = c("gray25", "gray50", "gray75"))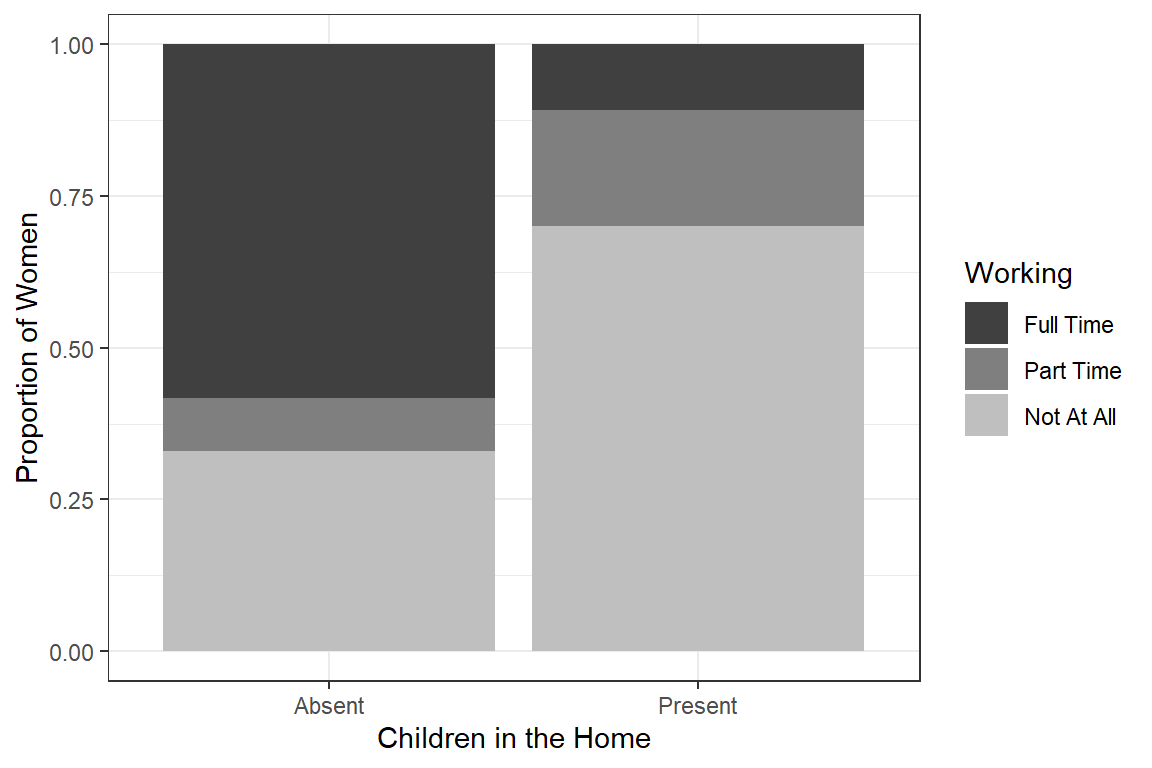
17.3 Hierarchical (nested) Logistic Regression
For an \(m-\)category polytomy dependent variable is respecified as a series of \(m – 1\) nested dichotomies. A single or combined levels of outcome compared to another single or combination of levels. Then they are analyzed using a series of binary logistic regressions, such that:
- Dichotomies selected based on theory
- Avoid redundancy
- Similar to contrast coding, but for outcome
For this dataset example, the outcome (partic) has \(3-\)categories, so we will investigate TWO nested dichotomies
- outcome =
working_any - outcome =
working_type
17.3.1 Role of Predictors on ANY working
Fit a regular logistic model with all three predictors regressed on the binary indicator for any working. Use the glm() function in the base \(R\) stats package.
fit_glm_1 <- glm(working_any ~ hincome + children + region,
data = df_wo,
family = binomial(link = "logit"))
summary(fit_glm_1)
Call:
glm(formula = working_any ~ hincome + children + region, family = binomial(link = "logit"),
data = df_wo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.26771 0.55296 2.293 0.0219 *
hincome -0.04534 0.02057 -2.204 0.0275 *
childrenPresent -1.60434 0.30187 -5.315 1.07e-07 ***
regionBc 0.34196 0.58504 0.585 0.5589
regionOntario 0.18778 0.46762 0.402 0.6880
regionPrairie 0.47186 0.55680 0.847 0.3967
regionQuebec -0.17310 0.49957 -0.347 0.7290
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 356.15 on 262 degrees of freedom
Residual deviance: 317.30 on 256 degrees of freedom
AIC: 331.3
Number of Fisher Scoring iterations: 4Check if region is statistically significant with the drop1() function from the base \(R\) stats package. This may be done with a Likelihood Ratio Test (test = "LRT", which is the same as test = "Chisq" for glm models).
# A tibble: 4 × 5
Df Deviance AIC LRT `Pr(>Chi)`
<dbl> <dbl> <dbl> <dbl> <dbl>
1 NA 317. 331. NA NA
2 1 322. 334. 5.13 0.0236
3 1 348. 360. 30.5 0.0000000326
4 4 320. 326. 2.43 0.657 Since the region doesn’t have exhibit any effect on odds a women is in the labor force, remove that predictor in the model to simplify to a ‘best’ final model. Also, center husband’s income at a value near the mean so the intercept has meaning.
fit_glm_2 <- glm(working_any ~ I(hincome - 14) + children,
data = df_wo,
family = binomial(link = "logit"))
summary(fit_glm_2)
Call:
glm(formula = working_any ~ I(hincome - 14) + children, family = binomial(link = "logit"),
data = df_wo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.74351 0.24312 3.058 0.00223 **
I(hincome - 14) -0.04231 0.01978 -2.139 0.03244 *
childrenPresent -1.57565 0.29226 -5.391 7e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 356.15 on 262 degrees of freedom
Residual deviance: 319.73 on 260 degrees of freedom
AIC: 325.73
Number of Fisher Scoring iterations: 4apaSupp::tab_glm(fit_glm_2,
var_labels = c("I(hincome - 14)" = "Husband's Income",
"children" = "Children in the Home"),
general_note = "The intercept corresponds to a home without children and a husband making the median salary of $14,000/yr.")Odds Ratio | Logit Scale | ||||||||
|---|---|---|---|---|---|---|---|---|---|
Variable | OR | 95% CI | b | (SE) | Wald | LRT | VIF | ||
Husband's Income | 0.96 | [0.92, 1.00] | -0.04 | (0.02) | .032* | .028* | 1.00 | ||
Children in the Home | < .001*** | 1.00 | |||||||
Absent | — | — | — | — | |||||
Present | 0.21 | [0.12, 0.36] | < .001 | (0.29) | < .001*** | ||||
(Intercept) | 0.74 | (0.24) | .002** | ||||||
pseudo-R² | .138 | ||||||||
Note. N = 263. CI = confidence interval; VIF = variance inflation factor. Significance denotes Wald t-tests for individual parameter estimates, as well as Likelihood Ratio Tests (LRT) for single-predictor deletion. Coefficient of determination displays Tjur's pseudo-R². The intercept corresponds to a home without children and a husband making the median salary of $14,000/yr. | |||||||||
* p < .05. ** p < .01. *** p < .001. | |||||||||
Interpretation:
Among women without children in the home and a husband making $14,000 annually, there is about a 2:1 odds she is in the workforce.
For each additional thousand dollars the husband makes, the odds ratio decreases by about 4 percent.
If there are children in the home, the odds of being in the workforce is nearly a fifth as large.
interactions::interact_plot(model = fit_glm_2,
pred = hincome,
modx = children,
interval = TRUE) +
theme_bw()
interactions::interact_plot(model = fit_glm_2,
pred = hincome,
modx = children,
interval = TRUE,
x.label = "Husband's Income, in $1,000's",
y.label = "Predicted Probability of\nWomen Being in the Workforce",
legend.main = "Children in the Home:",
colors = rep("black", 2)) +
geom_vline(xintercept = 14, color = "gray25") + # reference line for intercept
theme_bw() +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm"))
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_glm_2) %>%
data.frame() %>%
ggplot(aes(x = hincome,
y = fit)) +
geom_vline(xintercept = 14, color = "gray25") + # reference line for intercept
geom_ribbon(aes(ymin = fit - se,
ymax = fit + se,
fill = children),
alpha = .2) +
geom_line(aes(color = children,
linetype = children),
size = 1) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability of\nWomen Being in the Workforce",
fill = "Children in the Home:",
color = "Children in the Home:",
linetype = "Children in the Home:") +
theme(legend.position = c(1, 1),
legend.justification = c(1.1, 1.1),
legend.background = element_rect(color = "black"),
legend.key.width = unit(3, "cm")) +
coord_cartesian(ylim = c(0, 1))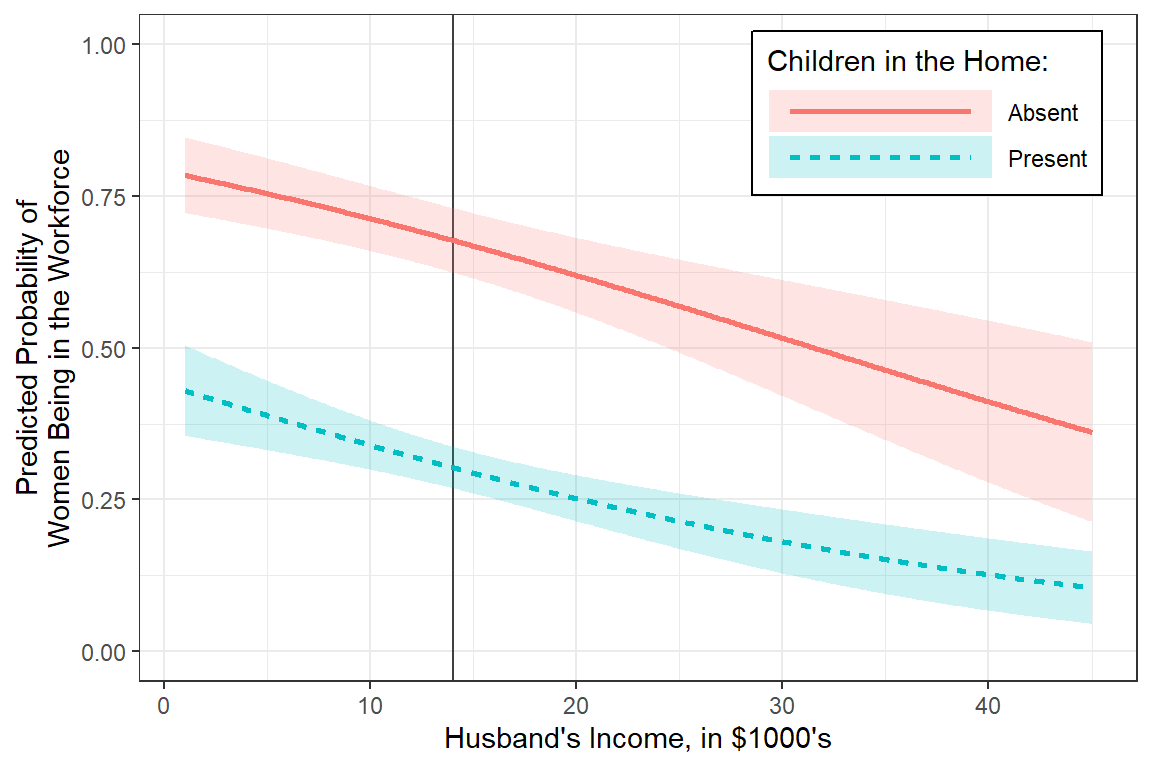
17.3.2 Role of Predictors on TYPE of work
Fit a regular logistic model with all three predictors regressed on the binary indicator for level/type of working.
fit_glm_3 <- glm(working_type ~ hincome + children + region,
data = df_wo,
family = binomial(link = "logit"))
summary(fit_glm_3)
Call:
glm(formula = working_type ~ hincome + children + region, family = binomial(link = "logit"),
data = df_wo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.76164 1.05718 3.558 0.000373 ***
hincome -0.10475 0.04032 -2.598 0.009383 **
childrenPresent -2.74781 0.56893 -4.830 1.37e-06 ***
regionBc -1.18248 1.02764 -1.151 0.249865
regionOntario -0.14876 0.84703 -0.176 0.860589
regionPrairie -0.39173 0.96310 -0.407 0.684200
regionQuebec 0.14842 0.93300 0.159 0.873612
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 144.34 on 107 degrees of freedom
Residual deviance: 101.84 on 101 degrees of freedom
(155 observations deleted due to missingness)
AIC: 115.84
Number of Fisher Scoring iterations: 5Check if region is statistically significant with the drop1() function from the base \(R\) stats package. This may be done with a Likelihood Ratio Test (test = "LRT", which is the same as test = "Chisq" for glm models).
# A tibble: 4 × 5
Df Deviance AIC LRT `Pr(>Chi)`
<dbl> <dbl> <dbl> <dbl> <dbl>
1 NA 102. 116. NA NA
2 1 110. 122. 7.84 0.00512
3 1 134. 146. 31.9 0.0000000162
4 4 104. 110. 2.65 0.618 Since the region doesn’t have exhibit any effect on odds a working women is in the labor force full time, remove that predictor in the model to simplify to a ‘best’ final model. Also, center husband’s income at a value near the mean so the intercept has meaning.
fit_glm_4 <- glm(working_type ~ I(hincome - 14) + children,
data = df_wo,
family = binomial(link = "logit"))
summary(fit_glm_4)
Call:
glm(formula = working_type ~ I(hincome - 14) + children, family = binomial(link = "logit"),
data = df_wo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.97602 0.43024 4.593 4.37e-06 ***
I(hincome - 14) -0.10727 0.03915 -2.740 0.00615 **
childrenPresent -2.65146 0.54108 -4.900 9.57e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 144.34 on 107 degrees of freedom
Residual deviance: 104.49 on 105 degrees of freedom
(155 observations deleted due to missingness)
AIC: 110.49
Number of Fisher Scoring iterations: 5apaSupp::tab_glms(list("Working at All" = fit_glm_2,
"Full vs. Part-Time" = fit_glm_4),
var_labels = c("I(hincome - 14)" = "Husband's Income",
"children" = "Children in the Home"),
general_note = "The intercept corresponds to a home without children and a husband making the median salary of $14,000/yr.")
| Working at All | Full vs. Part-Time | ||||
|---|---|---|---|---|---|---|
Variable | OR | 95% CI | p | OR | 95% CI | p |
Husband's Income | 0.96 | [0.92, 1.00] | .032* | 0.90 | [0.83, 0.97] | .006** |
Children in the Home | ||||||
Absent | — | — | — | — | ||
Present | 0.21 | [0.12, 0.36] | < .001*** | 0.07 | [0.02, 0.19] | < .001*** |
N | 263 | 108 | ||||
Fit Metrics | ||||||
AIC | 325.7 | 110.5 | ||||
BIC | 336.4 | 118.5 | ||||
pseudo-R² | ||||||
Tjur | .138 | .333 | ||||
McFadden | .102 | .276 | ||||
Note. Models fit to different samples. CI = confidence interval.Coefficient of determination estiamted with both Tjur and McFadden's psuedo R-squaredThe intercept corresponds to a home without children and a husband making the median salary of $14,000/yr. | ||||||
* p < .05. ** p < .01. *** p < .001. | ||||||
Interpretation:
Among working women without children in the home and a husband making $14,000 annually, there is more than 7:1 odds she is working full time verses part time.
For each additional thousand dollars the husband makes, the odds ratio decreases by about 10 percent.
If there are children in the home, the odds of being in the workforce is drastically reduced.
interactions::interact_plot(model = fit_glm_4,
pred = hincome,
modx = children,
interval = TRUE,
x.label = "Husband's Income, in $1,000's",
y.label = "Predicted Probability of\nWomen Being in the Workforce Full Time\nif they are working",
legend.main = "Children in the Home:",
modx.labels = c("Absent", "Present"),
colors = rep("black", 2)) +
geom_vline(xintercept = 14, color = "gray25") + # reference line for intercept
theme_bw() +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm"))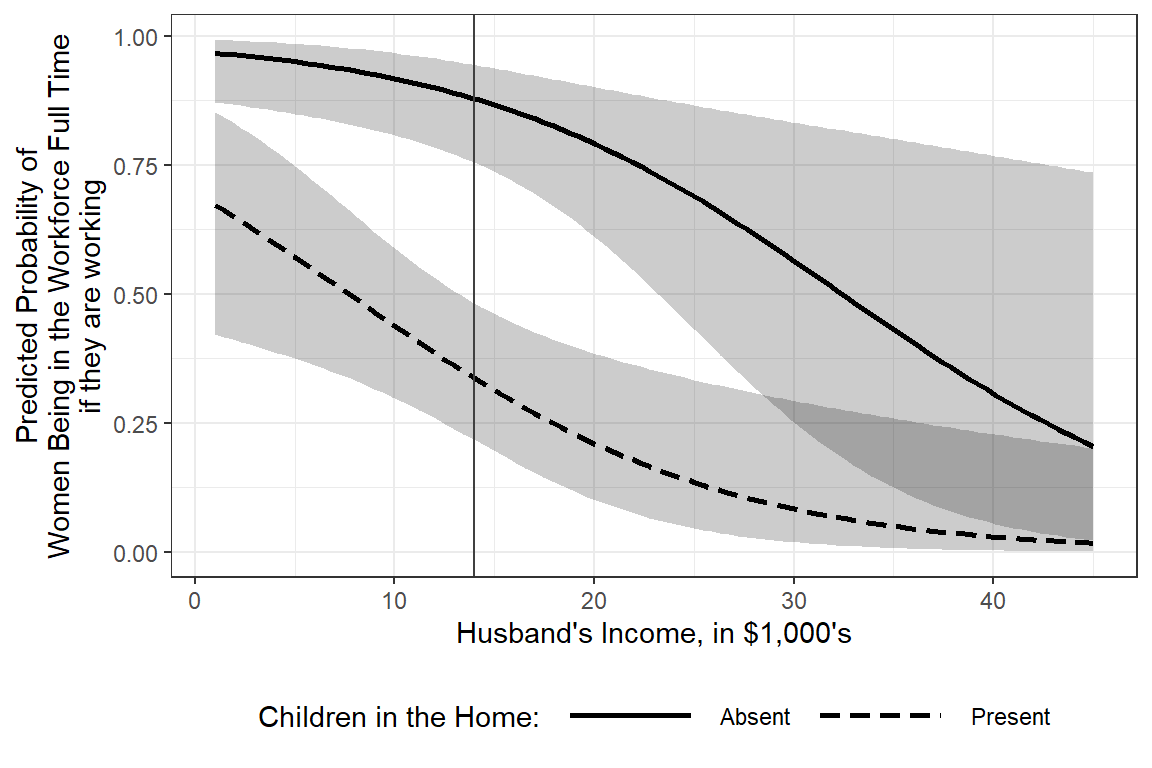
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_glm_4) %>%
data.frame() %>%
ggplot(aes(x = hincome,
y = fit,
color = children,
linetype = children)) +
geom_vline(xintercept = 14, color = "gray25") + # reference line for intercept
geom_line(size = 1) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability of\nWomen Being in the Workforce Full Time\nif they are working",
color = "Children in\nthe Home:",
linetype = "Children in\nthe Home:") +
theme(legend.position = c(1, 1),
legend.justification = c(1.1, 1.1),
legend.background = element_rect(color = "black")) +
coord_cartesian(ylim = c(0, 1))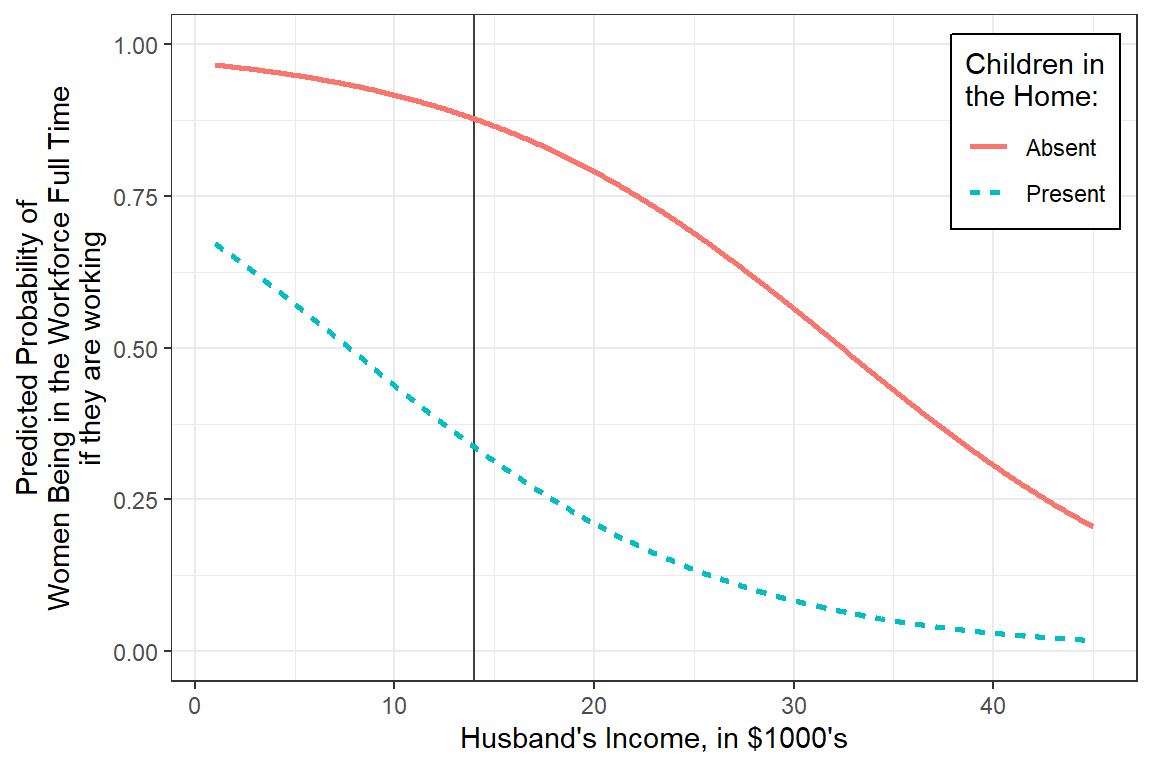
17.4 Multinomial (nominal) Logistic Regression
Multinomial Logistic Regression fits a single model by specifing a reference level of the outcome and comparing each additional level to it. In our case we will choose not working as the reference category adn get a set of parameter estimates (betas) for each of the two options part time and full time.
17.4.1 Fit Model 1: main effects only
Use multinom() function in the base \(R\) nnet package. You will also need the MASS and \(R\) package (only to compute MLEs). Make sure to remove cases with missing data on predictors before modeling or use the na.action = na.omit optin in the multinom() model command.
# weights: 24 (14 variable)
initial value 288.935032
iter 10 value 208.470682
iter 20 value 207.732796
iter 20 value 207.732796
iter 20 value 207.732796
final value 207.732796
convergedCall:
nnet::multinom(formula = working_ord ~ I(hincome - 14) + children +
region, data = df_wo)
Coefficients:
(Intercept) I(hincome - 14) childrenPresent regionBc regionOntario
Part Time -1.7521373 0.005261435 0.1462009 1.0863549 0.2856917
Full Time 0.7240428 -0.100034170 -2.6977927 -0.4599247 0.1135573
regionPrairie regionQuebec
Part Time 0.5747258 -0.1105184
Full Time 0.4681016 -0.3116829
Std. Errors:
(Intercept) I(hincome - 14) childrenPresent regionBc regionOntario
Part Time 0.7204798 0.02468887 0.4901621 0.7193077 0.6175050
Full Time 0.6102008 0.02901623 0.3876731 0.7837044 0.6175128
regionPrairie regionQuebec
Part Time 0.7259118 0.6873048
Full Time 0.7332449 0.6515172
Residual Deviance: 415.4656
AIC: 443.4656 17.4.2 Fit Model 2: only significant predictors
Reduce the model by removing the region variable.
# weights: 12 (6 variable)
initial value 288.935032
iter 10 value 211.456740
final value 211.440963
convergedCall:
nnet::multinom(formula = working_ord ~ I(hincome - 14) + children,
data = df_wo)
Coefficients:
(Intercept) I(hincome - 14) childrenPresent
Part Time -1.3357927 0.00688932 0.02149927
Full Time 0.6215469 -0.09723492 -2.55867912
Std. Errors:
(Intercept) I(hincome - 14) childrenPresent
Part Time 0.4340062 0.02345463 0.4690285
Full Time 0.2585136 0.02809670 0.3622077
Residual Deviance: 422.8819
AIC: 434.8819 17.4.3 Compre model fit
Check if we need to keep the region variable in our model.
# A tibble: 2 × 7
Model `Resid. df` `Resid. Dev` Test ` Df` `LR stat.` `Pr(Chi)`
<chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 I(hincome - 14) +… 520 423. "" NA NA NA
2 I(hincome - 14) +… 512 415. "1 v… 8 7.42 0.492# A tibble: 2 × 10
Name Model R2 R2_adjusted RMSE Sigma AIC_wt AICc_wt BIC_wt
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 fit_multnom_2 multinom 0.155 0.151 0.397 1.28 0.987 0.993 1.000e+0
2 fit_multnom_1 multinom 0.170 0.166 0.392 1.29 0.0135 0.00686 8.52 e-9
# ℹ 1 more variable: Performance_Score <dbl>17.4.4 Extract parameters
17.4.4.1 Logit Scale
Here is one way to extract the parameter estimates, but recall they are in terms of the logit or log-odds, not probability.
# A tibble: 6 × 6
y.level term estimate std.error statistic p.value
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Part Time (Intercept) -1.34 0.434 -3.08 0.0021
2 Part Time I(hincome - 14) 0.00689 0.0235 0.294 0.769
3 Part Time childrenPresent 0.0215 0.469 0.0458 0.963
4 Full Time (Intercept) 0.622 0.259 2.40 0.0162
5 Full Time I(hincome - 14) -0.0972 0.0281 -3.46 0.0005
6 Full Time childrenPresent -2.56 0.362 -7.06 0 17.4.4.2 Odds-Ratio Scale
The effects::allEffects() function provides probability estimates for each outcome level for different levels of the predictors.
model: working_ord ~ I(hincome - 14) + children
hincome effect (probability) for Not At All
hincome
1 10 20 30 40
0.4265713 0.5819837 0.6888795 0.7333353 0.7439897
hincome effect (probability) for Part Time
hincome
1 10 20 30 40
0.1041120 0.1511290 0.1916462 0.2185644 0.2375547
hincome effect (probability) for Full Time
hincome
1 10 20 30 40
0.46931674 0.26688731 0.11947430 0.04810031 0.01845552
children effect (probability) for Not At All
children
Absent Present
0.3339937 0.7122698
children effect (probability) for Part Time
children
Absent Present
0.08828253 0.19236144
children effect (probability) for Full Time
children
Absent Present
0.57772376 0.09536878 17.4.5 Tabulate parameters
The texreg package know how to handle this type of model and displays the parameters estimates in two separate columns.
coef. s.e. p
Part Time: (Intercept) -1.33579274 0.43400624 2.085214e-03
Part Time: I(hincome - 14) 0.00688932 0.02345463 7.689645e-01
Part Time: childrenPresent 0.02149927 0.46902849 9.634395e-01
Full Time: (Intercept) 0.62154688 0.25851357 1.620301e-02
Full Time: I(hincome - 14) -0.09723492 0.02809670 5.387245e-04
Full Time: childrenPresent -2.55867912 0.36220774 1.616364e-12
GOF dec. places
AIC 434.8819 TRUE
BIC 456.3149 TRUE
Log Likelihood -211.4410 TRUE
Deviance 422.8819 TRUE
Num. obs. 263.0000 FALSE
K 3.0000 FALSEtexreg::knitreg(fit_multnom_2,
custom.model.name = c("b (SE)"),
custom.coef.map = list("Part Time: (Intercept)" = "PT-BL: No children, Husband Earns $14,000/yr",
"Part Time: I(hincome - 14)" = "PT-Husband's Income, in $1,000's",
"Part Time: childrenPresent" = "PT-Children in the Home",
"Full Time: (Intercept)" = "FT-BL: No children, Husband Earns $14,000/yr",
"Full Time: I(hincome - 14)" = "FT-Husband's Income, in $1,000's",
"Full Time: childrenPresent" = "FT-Children in the Home"),
groups = list("Part Time" = 1:3,
"Full Time" = 4:6),
single.row = TRUE)| b (SE) | |
|---|---|
| Part Time | |
| PT-BL: No children, Husband Earns $14,000/yr | -1.34 (0.43)** |
| PT-Husband’s Income, in $1,000’s | 0.01 (0.02) |
| PT-Children in the Home | 0.02 (0.47) |
| Full Time | |
| FT-BL: No children, Husband Earns $14,000/yr | 0.62 (0.26)* |
| FT-Husband’s Income, in $1,000’s | -0.10 (0.03)*** |
| FT-Children in the Home | -2.56 (0.36)*** |
| AIC | 434.88 |
| BIC | 456.31 |
| Log Likelihood | -211.44 |
| Deviance | 422.88 |
| Num. obs. | 263 |
| K | 3 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
(Intercept) I(hincome - 14) childrenPresent
Part Time -1.3357927 0.00688932 0.02149927
Full Time 0.6215469 -0.09723492 -2.55867912 (Intercept) I(hincome - 14) childrenPresent
Part Time 0.2629496 1.0069131 1.02173205
Full Time 1.8618058 0.9073428 0.07740692, , Part Time
2.5 % 97.5 %
(Intercept) 0.1123171 0.6156011
I(hincome - 14) 0.9616729 1.0542816
childrenPresent 0.4074734 2.5619744
, , Full Time
2.5 % 97.5 %
(Intercept) 1.12172715 3.0901640
I(hincome - 14) 0.85872767 0.9587102
childrenPresent 0.03805993 0.157431517.4.6 Plot Predicted Probabilities
NOTE: I’m not sure how to use the
interactions::interact_plot()function with multinomial models.
17.4.6.1 Manually Compute
- estimates for probabilities and the associated 95% confidence intervals
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_multnom_2)
hincome*children effect (probability) for Not At All
children
hincome Absent Present
20 0.4323538 0.7350680
30 0.5929483 0.7516619
40 0.6834699 0.7502613
hincome*children effect (probability) for Part Time
children
hincome Absent Present
20 0.1184851 0.2058207
30 0.1740850 0.2254779
40 0.2149730 0.2411093
hincome*children effect (probability) for Full Time
children
hincome Absent Present
20 0.4491611 0.059111252
30 0.2329667 0.022860160
40 0.1015571 0.00862945417.4.6.2 Wrange
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_multnom_2) %>%
data.frame() # A tibble: 6 × 26
hincome children prob.Not.At.All prob.Part.Time prob.Full.Time
<dbl> <fct> <dbl> <dbl> <dbl>
1 20 Absent 0.432 0.118 0.449
2 30 Absent 0.593 0.174 0.233
3 40 Absent 0.683 0.215 0.102
4 20 Present 0.735 0.206 0.0591
5 30 Present 0.752 0.225 0.0229
6 40 Present 0.750 0.241 0.00863
# ℹ 21 more variables: logit.Not.At.All <dbl>, logit.Part.Time <dbl>,
# logit.Full.Time <dbl>, se.prob.Not.At.All <dbl>, se.prob.Part.Time <dbl>,
# se.prob.Full.Time <dbl>, se.logit.Not.At.All <dbl>,
# se.logit.Part.Time <dbl>, se.logit.Full.Time <dbl>,
# L.prob.Not.At.All <dbl>, L.prob.Part.Time <dbl>, L.prob.Full.Time <dbl>,
# U.prob.Not.At.All <dbl>, U.prob.Part.Time <dbl>, U.prob.Full.Time <dbl>,
# L.logit.Not.At.All <dbl>, L.logit.Part.Time <dbl>, …effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_multnom_2) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time)# A tibble: 6 × 11
hincome children est_fit_none est_fit_part est_fit_full est_lower_none
<dbl> <fct> <dbl> <dbl> <dbl> <dbl>
1 20 Absent 0.432 0.118 0.449 0.306
2 30 Absent 0.593 0.174 0.233 0.399
3 40 Absent 0.683 0.215 0.102 0.418
4 20 Present 0.735 0.206 0.0591 0.655
5 30 Present 0.752 0.225 0.0229 0.597
6 40 Present 0.750 0.241 0.00863 0.486
# ℹ 5 more variables: est_lower_part <dbl>, est_lower_full <dbl>,
# est_upper_none <dbl>, est_upper_part <dbl>, est_upper_full <dbl>effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_multnom_2) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit")# A tibble: 18 × 6
hincome children work_level fit lower upper
<dbl> <fct> <chr> <dbl> <dbl> <dbl>
1 20 Absent none 0.432 0.306 0.568
2 20 Absent part 0.118 0.0568 0.231
3 20 Absent full 0.449 0.318 0.588
4 30 Absent none 0.593 0.399 0.762
5 30 Absent part 0.174 0.0728 0.361
6 30 Absent full 0.233 0.104 0.443
7 40 Absent none 0.683 0.418 0.866
8 40 Absent part 0.215 0.0692 0.502
9 40 Absent full 0.102 0.0256 0.327
10 20 Present none 0.735 0.655 0.802
11 20 Present part 0.206 0.145 0.283
12 20 Present full 0.0591 0.0319 0.107
13 30 Present none 0.752 0.597 0.861
14 30 Present part 0.225 0.120 0.383
15 30 Present full 0.0229 0.00782 0.0649
16 40 Present none 0.750 0.486 0.905
17 40 Present part 0.241 0.0887 0.509
18 40 Present full 0.00863 0.00176 0.041117.4.6.3 Plot, version 1
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_multnom_2) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit") %>%
dplyr::mutate(work_level = work_level %>%
factor() %>%
forcats::fct_recode("Not at All" = "none",
"Part Time" = "part",
"Full Time" = "full") %>%
forcats::fct_rev()) %>%
ggplot(aes(x = hincome,
y = fit)) +
geom_vline(xintercept = 14, color = "gray50") + # reference line for intercept
geom_hline(yintercept = 0.5, color = "gray50") + # 50% chance line for reference
geom_ribbon(aes(ymin = lower,
ymax = upper,
fill = work_level),
alpha = .3) +
geom_line(aes(color = work_level,
linetype = work_level),
size = 1) +
facet_grid(. ~ children, labeller = label_both) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability",
color = "Woman Works:",
fill = "Woman Works:",
linetype = "Woman Works:") +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm")) +
coord_cartesian(ylim = c(0, 1)) +
scale_linetype_manual(values = c("solid", "longdash", "dotted"))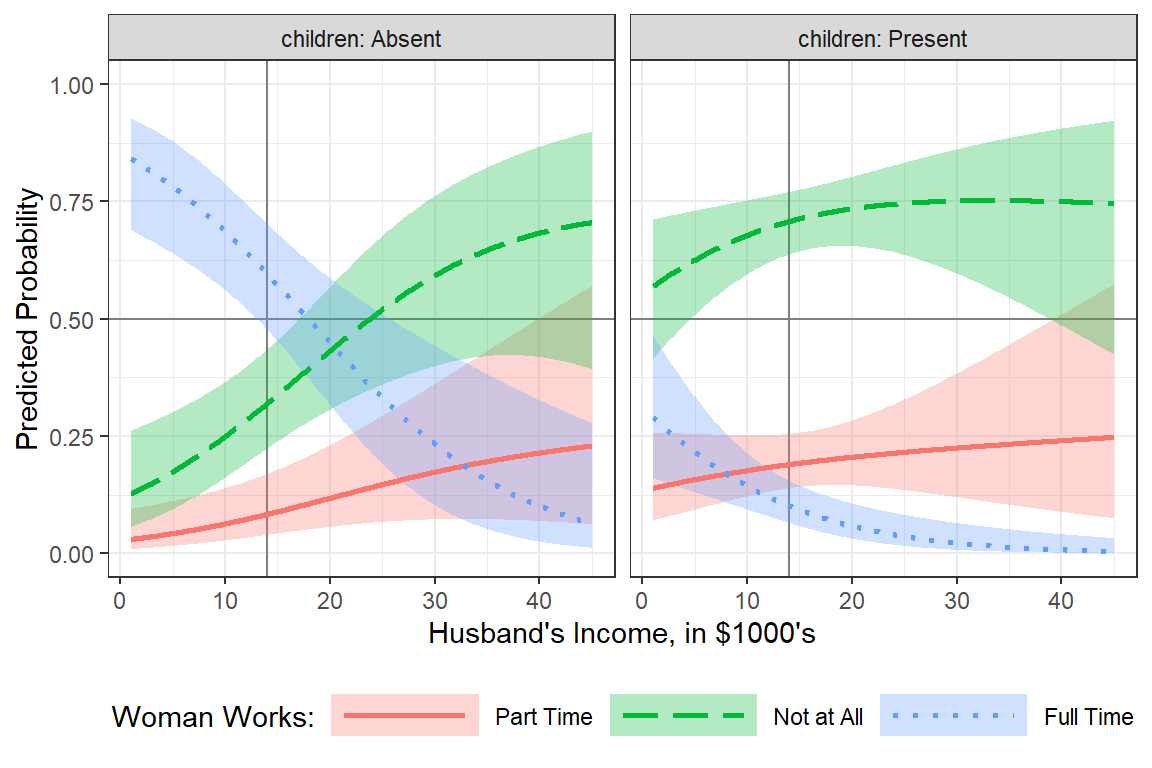
17.4.6.4 Plot, version 2
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_multnom_2) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit") %>%
dplyr::mutate(work_level = factor(work_level,
levels = c("none", "part", "full"),
labels = c("Not at All",
"Part Time",
"Full Time"))) %>%
ggplot(aes(x = hincome,
y = fit)) +
geom_vline(xintercept = 14, color = "gray50") + # reference line for intercept
geom_hline(yintercept = 0.5, color = "gray50") + # 50% chance line for reference
geom_ribbon(aes(ymin = lower,
ymax = upper,
fill = children),
alpha = .3) +
geom_line(aes(color = children,
linetype = children),
size = 1) +
facet_grid(. ~ work_level) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability",
color = "Children in the Home:",
fill = "Children in the Home:",
linetype = "Children in the Home:") +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm")) +
coord_cartesian(ylim = c(0, 1)) +
scale_linetype_manual(values = c("solid", "longdash")) +
scale_fill_manual(values = c("dodgerblue", "coral3"))+
scale_color_manual(values = c("dodgerblue", "coral3"))
17.4.7 Interpretation
Among women without children in the home and a husband making $14,000 annually, there is about 1:4 odds she is working part time verses not at all. and a 1.8:1 odds she is working full time.
For each additional thousand dollars the husband makes, the odds ratio decreases by about 10 percent that she is working full time, yet stay the same that she works part time.
If there are children in the home, the odds of working part time increase by 2 percent and there is a very unlikely change she works full time.
17.5 Proportional-odds (ordinal) Logistic Regression
This type of logisit regression model forces the predictors to have similar relationship with the outcome (slopes), but different means (intercepts). This is called the proportional odds assumption.
17.5.1 Fit the Model
Use polr() function in the base \(R\) MASS package. While outcome variable (dependent variable, “Y”) may be a regular factor, it is preferable to specify it as an ordered factor.
Call:
MASS::polr(formula = working_ord ~ hincome + children, data = df_wo)
Coefficients:
Value Std. Error t value
hincome -0.0539 0.01949 -2.766
childrenPresent -1.9720 0.28695 -6.872
Intercepts:
Value Std. Error t value
Not At All|Part Time -1.8520 0.3863 -4.7943
Part Time|Full Time -0.9409 0.3699 -2.5435
Residual Deviance: 441.663
AIC: 449.663 17.5.2 Extract Parameters
17.5.2.1 Logit Scale
Not At All|Part Time Part Time|Full Time
-1.8520378 -0.9409261 2.5 % 97.5 %
hincome -0.09323274 -0.0166527
childrenPresent -2.54479931 -1.417748717.5.2.2 Odds-Ratio Scale
hincome childrenPresent
0.9475262 0.1391841 2.5 % 97.5 %
hincome 0.9109815 0.9834852
childrenPresent 0.0784888 0.242258817.5.2.3 Predicted Probabilities
model: working_ord ~ hincome + children
hincome effect (probability) for Not At All
hincome
1 10 20 30 40
0.3968718 0.5166413 0.6469356 0.7585238 0.8433820
hincome effect (probability) for Part Time
hincome
1 10 20 30 40
0.22384583 0.21001062 0.17311759 0.12800001 0.08713914
hincome effect (probability) for Full Time
hincome
1 10 20 30 40
0.37928237 0.27334810 0.17994676 0.11347618 0.06947888
children effect (probability) for Not At All
children
Absent Present
0.2579513 0.7140863
children effect (probability) for Part Time
children
Absent Present
0.2057297 0.1472491
children effect (probability) for Full Time
children
Absent Present
0.5363190 0.1386646 17.5.3 Tabulate parameters
texreg::knitreg(fit_polr_1,
custom.model.name = "b (SE)",
custom.coef.map = list("hincome" = "Husband's Income, $1000's",
"childrenPresent" = "Children in the Home",
"Not At All|Part Time" = "Not At All vs.Part Time",
"Part Time|Full Time" = "Part Time vs.Full Time"),
groups = list("Coefficents" = 1:2,
"Intercepts" = 3:4),
caption = "Proportional-odds (ordinal) Logistic Regression",
caption.above = TRUE,
single.row = TRUE)| b (SE) | |
|---|---|
| Coefficents | |
| Husband’s Income, $1000’s | -0.05 (0.02)** |
| Children in the Home | -1.97 (0.29)*** |
| Intercepts | |
| Not At All vs.Part Time | -1.85 (0.39)*** |
| Part Time vs.Full Time | -0.94 (0.37)* |
| AIC | 449.66 |
| BIC | 463.95 |
| Log Likelihood | -220.83 |
| Deviance | 441.66 |
| Num. obs. | 263 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
17.5.4 Plot Predicted Probabilities
17.5.4.1 Manually Compute
- estimates for probabilities and the associated 95% confidence intervals
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_polr_1)
hincome*children effect (probability) for Not At All
children
hincome Absent Present
20 0.3156092 0.7681570
30 0.4415146 0.8502980
40 0.5754175 0.9068653
hincome*children effect (probability) for Part Time
children
hincome Absent Present
20 0.2186091 0.12362226
30 0.2213518 0.08359281
40 0.1957828 0.05347906
hincome*children effect (probability) for Full Time
children
hincome Absent Present
20 0.4657817 0.10822076
30 0.3371336 0.06610916
40 0.2287997 0.0396556317.5.4.2 Wrangle
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_polr_1) %>%
data.frame()# A tibble: 6 × 26
hincome children prob.Not.At.All prob.Part.Time prob.Full.Time
<dbl> <fct> <dbl> <dbl> <dbl>
1 20 Absent 0.316 0.219 0.466
2 30 Absent 0.442 0.221 0.337
3 40 Absent 0.575 0.196 0.229
4 20 Present 0.768 0.124 0.108
5 30 Present 0.850 0.0836 0.0661
6 40 Present 0.907 0.0535 0.0397
# ℹ 21 more variables: logit.Not.At.All <dbl>, logit.Part.Time <dbl>,
# logit.Full.Time <dbl>, se.prob.Not.At.All <dbl>, se.prob.Part.Time <dbl>,
# se.prob.Full.Time <dbl>, se.logit.Not.At.All <dbl>,
# se.logit.Part.Time <dbl>, se.logit.Full.Time <dbl>,
# L.prob.Not.At.All <dbl>, L.prob.Part.Time <dbl>, L.prob.Full.Time <dbl>,
# U.prob.Not.At.All <dbl>, U.prob.Part.Time <dbl>, U.prob.Full.Time <dbl>,
# L.logit.Not.At.All <dbl>, L.logit.Part.Time <dbl>, …effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_polr_1) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time)# A tibble: 6 × 11
hincome children est_fit_none est_fit_part est_fit_full est_lower_none
<dbl> <fct> <dbl> <dbl> <dbl> <dbl>
1 20 Absent 0.316 0.219 0.466 0.217
2 30 Absent 0.442 0.221 0.337 0.274
3 40 Absent 0.575 0.196 0.229 0.320
4 20 Present 0.768 0.124 0.108 0.692
5 30 Present 0.850 0.0836 0.0661 0.741
6 40 Present 0.907 0.0535 0.0397 0.775
# ℹ 5 more variables: est_lower_part <dbl>, est_lower_full <dbl>,
# est_upper_none <dbl>, est_upper_part <dbl>, est_upper_full <dbl>effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = c(20, 30, 40)),
mod = fit_polr_1) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit")# A tibble: 18 × 6
hincome children work_level fit lower upper
<dbl> <fct> <chr> <dbl> <dbl> <dbl>
1 20 Absent none 0.316 0.217 0.435
2 20 Absent part 0.219 0.163 0.286
3 20 Absent full 0.466 0.346 0.589
4 30 Absent none 0.442 0.274 0.623
5 30 Absent part 0.221 0.165 0.291
6 30 Absent full 0.337 0.195 0.516
7 40 Absent none 0.575 0.320 0.796
8 40 Absent part 0.196 0.122 0.299
9 40 Absent full 0.229 0.0926 0.463
10 20 Present none 0.768 0.692 0.830
11 20 Present part 0.124 0.0875 0.172
12 20 Present full 0.108 0.0716 0.160
13 30 Present none 0.850 0.741 0.919
14 30 Present part 0.0836 0.0467 0.145
15 30 Present full 0.0661 0.0327 0.129
16 40 Present none 0.907 0.775 0.965
17 40 Present part 0.0535 0.0210 0.129
18 40 Present full 0.0397 0.0138 0.10917.5.4.3 Plot, version 1
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_polr_1) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit") %>%
dplyr::mutate(work_level = work_level %>%
factor() %>%
forcats::fct_recode("Not at All" = "none",
"Part Time" = "part",
"Full Time" = "full") %>%
forcats::fct_rev()) %>%
ggplot(aes(x = hincome,
y = fit)) +
geom_vline(xintercept = 14, color = "gray50") + # reference line for intercept
geom_hline(yintercept = 0.5, color = "gray50") + # 50% chance line for reference
geom_ribbon(aes(ymin = lower,
ymax = upper,
fill = work_level),
alpha = .3) +
geom_line(aes(color = work_level,
linetype = work_level),
size = 1) +
facet_grid(. ~ children, labeller = label_both) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability",
color = "Woman Works:",
fill = "Woman Works:",
linetype = "Woman Works:") +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm")) +
coord_cartesian(ylim = c(0, 1)) +
scale_linetype_manual(values = c("solid", "longdash", "dotted"))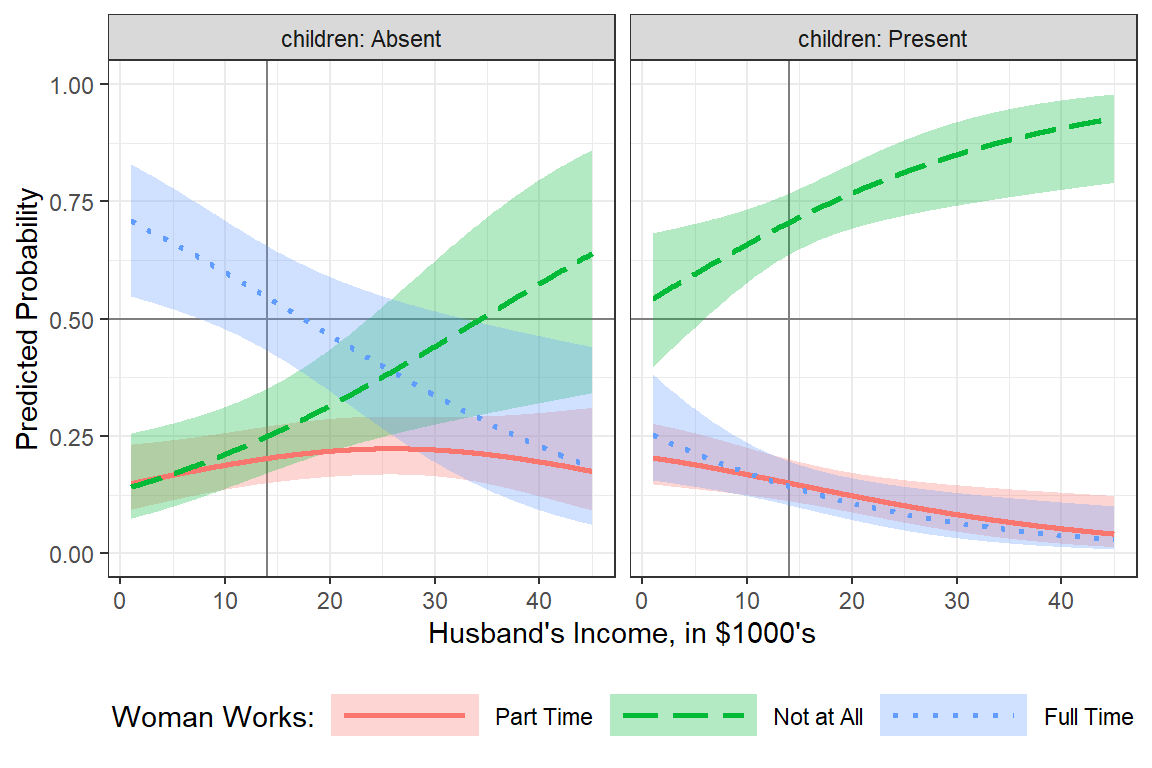
17.5.4.4 Plot, version 2
effects::Effect(focal.predictors = c("hincome", "children"),
xlevels = list(hincome = seq(from = 1, to = 45, by = .1)),
mod = fit_polr_1) %>%
data.frame() %>%
dplyr::select(hincome, children,
starts_with("prob"),
starts_with("L.prob"),
starts_with("U.prob")) %>%
dplyr::rename(est_fit_none = prob.Not.At.All,
est_fit_part = prob.Part.Time,
est_fit_full = prob.Full.Time,
est_lower_none = L.prob.Not.At.All,
est_lower_part = L.prob.Part.Time,
est_lower_full = L.prob.Full.Time,
est_upper_none = U.prob.Not.At.All,
est_upper_part = U.prob.Part.Time,
est_upper_full = U.prob.Full.Time) %>%
tidyr::pivot_longer(cols = starts_with("est"),
names_to = c(".value", "work_level"),
names_pattern = "est_(.*)_(.*)",
values_to = "fit") %>%
dplyr::mutate(work_level = factor(work_level,
levels = c("none", "part", "full"),
labels = c("Not at All",
"Part Time",
"Full Time"))) %>%
ggplot(aes(x = hincome,
y = fit)) +
geom_vline(xintercept = 14, color = "gray50") + # reference line for intercept
geom_hline(yintercept = 0.5, color = "gray50") + # 50% chance line for reference
geom_ribbon(aes(ymin = lower,
ymax = upper,
fill = children),
alpha = .3) +
geom_line(aes(color = children,
linetype = children),
size = 1) +
facet_grid(. ~ work_level) +
theme_bw() +
labs(x = "Husband's Income, in $1000's",
y = "Predicted Probability",
color = "Children in the Home:",
fill = "Children in the Home:",
linetype = "Children in the Home:") +
theme(legend.position = "bottom",
legend.key.width = unit(2, "cm")) +
coord_cartesian(ylim = c(0, 1)) +
scale_linetype_manual(values = c("solid", "longdash")) +
scale_fill_manual(values = c("dodgerblue", "coral3"))+
scale_color_manual(values = c("dodgerblue", "coral3"))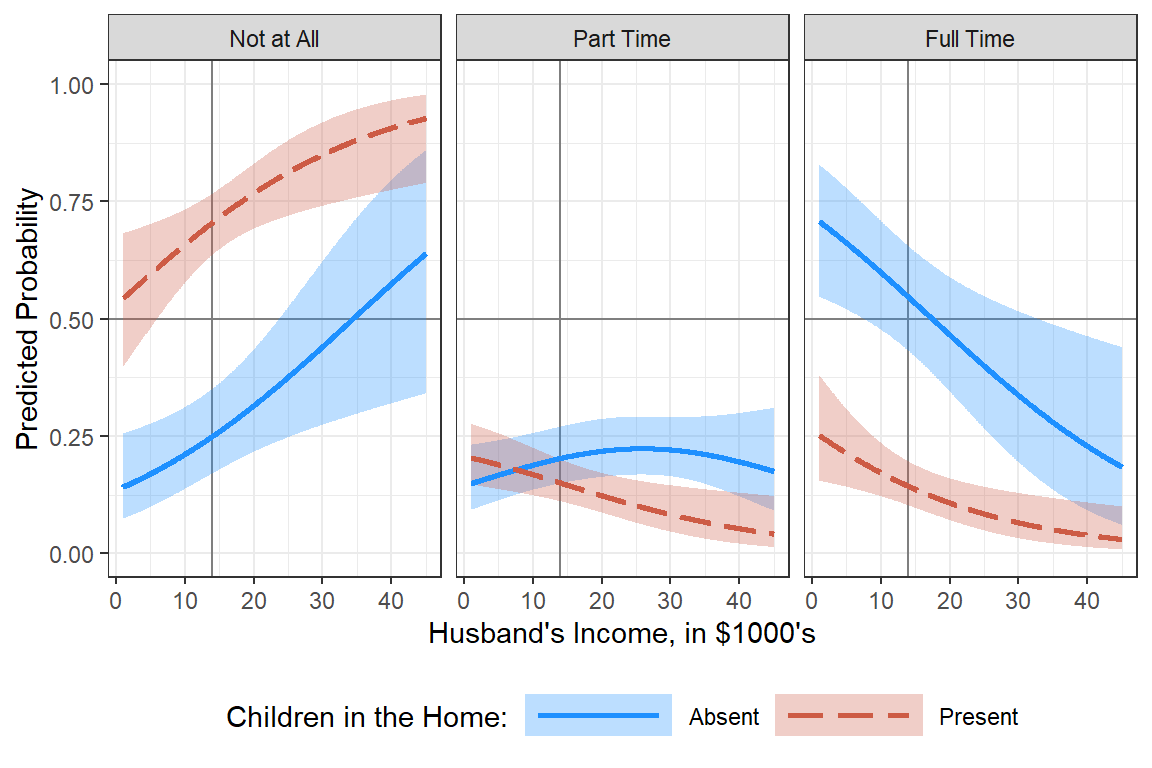
17.5.5 Interpretation
Among women without children in the home and a husband making $14,000 annually, there is a 26% chance she is not working, 21% change she is working part time and just over a 53% change she is working full time.
For each additional thousand dollars the husband makes, the odds ratio decreases by about 5 percent that she is working part time vs not at all and 5% that she is working full time vs part time.
If there are children in the home, the odds ratio of working part time vs not at all decreases by 86% and similartly the odds ratio fo working full time vs part time also decreases by 86%.
17.6 Compare Model Fits: Multinomial vs. Ordinal
The multinomail and proportional-odds models aren’t truely nested, so you can NOT conduct a Likelihood-Ratio Test (aka Deviance Difference Test) with the anova() command.
You can use the performance::compare_performance() command to compare overal model performance via the Bayes factor (BF).
# A tibble: 2 × 11
Name Model RMSE Sigma R2 R2_adjusted R2_Nagelkerke AIC_wt AICc_wt
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 fit_multno… mult… 0.397 1.28 0.155 0.151 NA 9.99e-1 9.99e-1
2 fit_polr_1 polr 1.60 1.30 NA NA 0.236 6.17e-4 6.72e-4
# ℹ 2 more variables: BIC_wt <dbl>, Performance_Score <dbl>